
Data Science
Effizienter durch das Erkennen und Verstehen verborgener Zusammenhänge
Täglich werden mehrere Petabytes an neuen Daten gesammelt. Sie sollen helfen, Kunden besser zu verstehen, Maschinen effizienter einzusetzen und Zusammenhänge zu erkennen, deren Existenz man niemals vermutet hätte. Doch wie kann eine nahezu unerschöpfliche Menge an einfachen Daten in nützliche Erkenntnisse für Ihr Geschäft transformiert werden? Die Antwort lautet: durch Data Science. Was wir Ihnen bieten:
- Data Processing
- Data Visualisation
- Data Profiling
- Data Cleansing
- Machine Learning
Kompetenzen
Wir bieten Ihnen:
- Entwicklung datengetriebener Produkte innerhalb und außerhalb von Cloud-Infrastrukturen
- Definition individueller Datenstrategien und -architekturen
- Stream Processing, um flexibel mit riesigen Datenmengen umgehen zu können
- Machine-Learning- und Deep-Learning-Algorithmen u. a. zur Erkennung von Mustern bzw. Klassifizierung von Daten
- Umfangreiche Erfahrungen mit Datenbanken (SQL und NoSQL), Data Warehouses und Data Lakes
- Datengetriebene Entscheidungsunterstützung mit aktuellen BI-Tools
- Visualisierung komplexer Datenzusammenhänge
Unser Data-Science-Portfolio umfasst vor allem folgende Anwendungsfälle:
- Natural Language Understanding: Identifizieren von Schlüsselinformationen in natürlichsprachlichen Texten wie E-Mails
- Pattern Recognition: Erkennen versteckter Muster in den Daten wie Kaufgewohnheiten spezieller Kundengruppen
- Object Detection: Erkennen von Objekten in (audio-)visuellen Medien wie Werkstücke in Augmented-Reality-Umgebungen
- Anomaly Detection: Erkennen von Ausreißern in den Daten wie z. B. ungewöhnliche Banktransaktionen
Technologien
Mithilfe der richtigen Technologien und Methoden verschaffen wir Ihren Data-Science-Projekten den entscheidenden Vorteil. Weitreichende Erfahrungen in der Softwareentwicklung in unterschiedlichen Branchen ermöglichen es uns, die richtige Lösung für jede Herausforderung zu finden. Wir verwenden unter anderem:
- Application Frameworks für skalierbare, fehlertolerante Echtzeitdatenverarbeitung
- Spark
- Hadoop
- Kafka
- Spring Cloud Data Flow
- Machine Learning Frameworks
- Keras (mit Tensorflow und CNTK als Backends)
- Deeplearning4J
- scikit-learn
- Moderne Entwicklungsinfrastruktur
- Microsoft Azure
- Amazon Web Services
- Google Cloud Platform
- Kubernetes
Methodisches Vorgehen
Für Ihren Erfolg setzen wir auf Prozesse, die als Industriestandard etabliert sind. Im Bereich Data Science nutzen wir daher das bewährte Vorgehensmodell CRISP-DM (Cross-industry standard process for data mining). Wir bedienen damit den vollständigen Lebenszyklus datengetriebener Dienste: die gemeinsame Problemdefinition, die Modellierung der Domäne (Machine Learning), schließlich die Skalierung auf Big Data sowie Wartung und Evolution. Integriert in Scrum und begleitet durch ein effektives Risikomanagement bringen wir Ihre datengetriebenen Produkte schnell und zuverlässig auf den Markt.
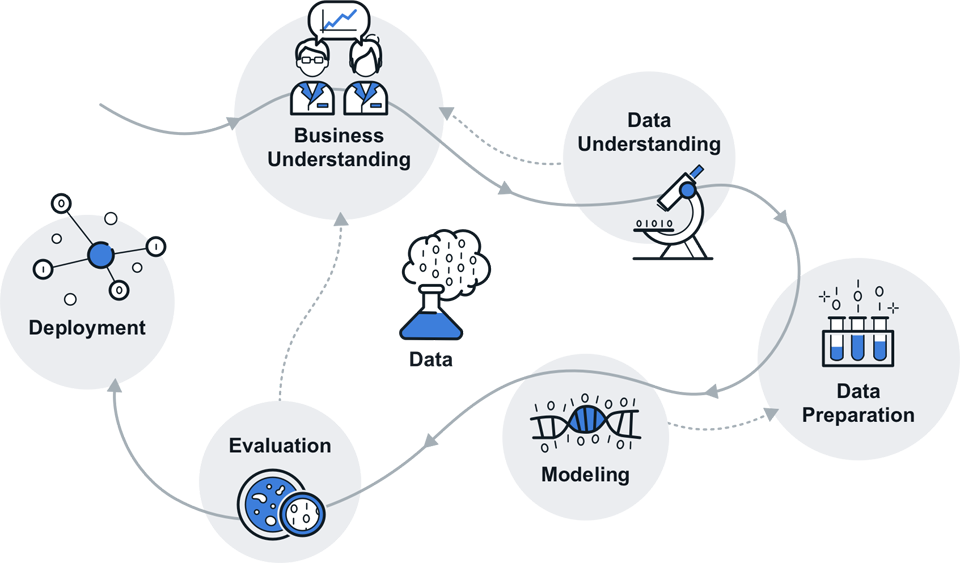
- Business Understanding: Schaffen eines gemeinsamen Problemverständnisses und Erarbeitung von Zielen
- Data Understanding: Untersuchung und Bewertung aller verfügbaren Daten
- Data Preparation: Bereinigung, Reorganisation und Normalisierung der Daten
- Modeling: Training intelligenter Modelle zur Klassifikation von Daten und Vorhersage neuer Ereignisse
- Evaluation: Bewertung der entwickelten Modelle anhand gemeinsamer Metriken
- Deployment: Inproduktionsnahme des datengetriebenen Produkts sowie Skalierung auf Big Data
Beispielprojekte Data Science
- Effizienz, Performance und Genauigkeit
- Usability
- Abdeckung der vollständigen Systemkette (Fahrzeug, Backend, Frontend, Apps)
- Frequenzanalyse
- Webfrontend
- Data Science
- Erneuerbare Energien
- powercloud
- IoT
- Cloud-native
- Serverless Computing
- E-Carsharing
Ihre Ansprechperson

Unser Geschäftsführer Artur Schiefer berät Sie zu unseren Individuallösungen, die Ihrem Unternehmen den technologischen Vorsprung verschaffen.