
Data science
Improving efficiency by recognising and understanding hidden connections
Several petabytes of new data are collected every day. They help to understand customers better, use machines more efficiently and recognise connections that would otherwise never have been identified. But how can an almost inexhaustible amount of simple data be transformed into useful insights for your business? Data science is the answer. What we offer you:
- Data processing
- Data visualisation
- Data profiling
- Data cleansing
- Machine learning
Capabilities
We provide the following:
- We develop data-driven products within and outside of cloud infrastructures
- We define individual data strategies and architectures
- Stream processing for handling huge amounts of data flexibly
- Machine learning and deep learning algorithms, e.g. for recognising patterns and classifying data
- Extensive experience with databases (SQL and NoSQL), data warehouses and data lakes
- Data-driven decision support using current BI tools
- Visualisations of complex data relationships
Our data science portfolio primarily covers the following applications:
- Natural language understanding: identifying key information in natural language texts, such as e-mails
- Pattern recognition: detecting hidden patterns in the data, such as buying habits of specific customer groups
- Object detection: detecting objects in (audio)visual media, such as workpieces in augmented reality environments
- Anomaly detection: detecting outliers in the data, such as unusual bank transactions
Technologies
With the right technologies and methods, we give your data science projects a crucial advantage. We can find the right solution for any problem thanks to our extensive experience of software development in various industries. We use:
- Application frameworks for scalable, fault-tolerant real-time data processing
- Spark
- Hadoop
- Kafka
- Spring Cloud Data Flow
- Machine Learning Frameworks
- Keras (with Tensorflow and CNTK as back ends)
- Deeplearning4J
- scikit-learn
- Modern development infrastructure
- Microsoft Azure
- Amazon Web Services
- Google Cloud Platform
- Kubernetes
Methodical approach
To ensure your success, we rely on processes that are established as industry standards. In the area of data science, we use the proven CRISP-DM (CRoss-Industry Standard Process for Data Mining) process model. In this way, we cover the complete life cycle of data-driven services: joint problem definition, domain modelling (machine learning), ultimately scaling up to big data systems, maintenance and evolution. We bring your data-driven products to market quickly and reliably, integrated in Scrum and accompanied by effective risk management.
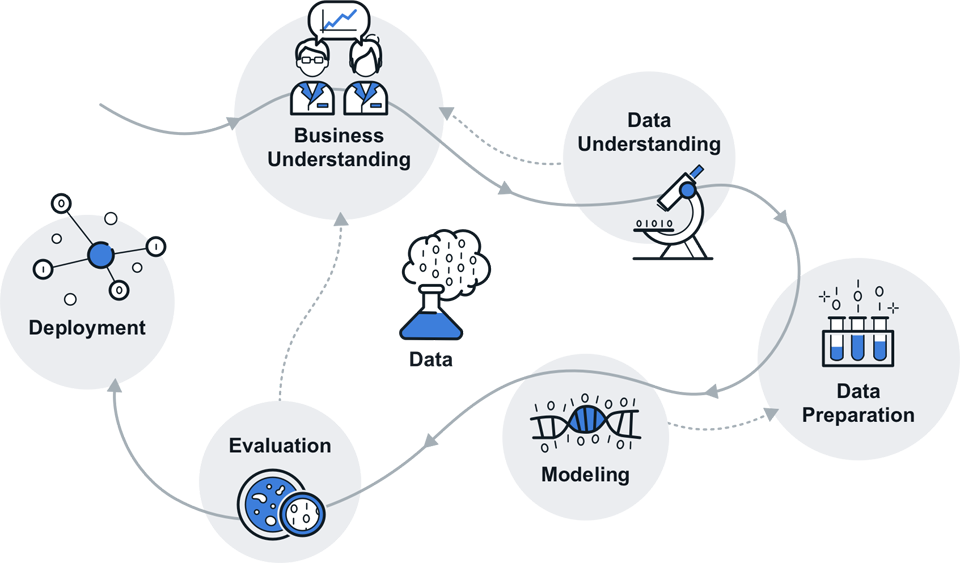
- Business understanding: creating a common understanding of the problem and formulating goals
- Data understanding: examining and evaluating all available data
- Data preparation: cleaning, reorganising and normalising the data
- Modelling: training intelligent models to classify data and predict new events
- Evaluation: evaluating the developed models against common metrics
- Deployment: going live with the data-driven product and scaling up to big data systems
Data science example projects
- Efficiency, performance and accuracy
- Usability
- Covers the complete system chain (vehicles, back end, front end, apps)
- Frequency Analysis
- Webfrontend
- Data Science
- Renewable Energies
- powercloud
- IoT
- Cloud-native
- serverless computing
- E-Carsharing
Your contact

Our Managing Director Artur Schiefer will advise you on our custom solutions that will give your company the technological lead.